Book of Nutanix Cloud Clusters
Nutanix Cloud Clusters on AWS
Based on: PC 2023.3 | AOS 6.7
» Download this section as PDF (opens in a new tab/window)
Nutanix Cloud Clusters (NC2) on AWS provides on-demand clusters running in target cloud environments using bare metal resources. This allows for true on-demand capacity with the simplicity of the Nutanix platform you know. Once provisioned the cluster appears like any traditional AHV cluster, just running in a cloud providers datacenters.
Supported Configurations
The solution is applicable to the configurations below (list may be incomplete, refer to documentation for a fully supported list):
Core Use Case(s):
- On-Demand / burst capacity
- Backup / DR
- Cloud Native
- Geo Expansion / DC consolidation
- App migration
- Etc.
Management interfaces(s):
- Nutanix Clusters Portal - Provisioning
- Prism Central (PC) - Nutanix Management
- AWS Console - AWS Management
Supported Environment(s):
- Cloud:
- AWS
- Azure
- EC2 Metal Instance Types:
- i3.metal
- m5d.metal
- z1d.metal
- i3en.metal
- g4dn.metal
- i4i.metal
- m6d.metal
Upgrades:
- Part of AOS
Compatible Features:
- AOS Features
- AWS Services
Key terms / Constructs
The following key items are used throughout this section and defined in the following:
- Nutanix Clusters Portal
- The Nutanix Clusters Portal is responsible for handling cluster provisioning requests and interacting with AWS and the provisioned hosts. It creates cluster specific details and handles the dynamic CloudFormation stack creation.
- Region
- A geographic landmass or area where multiple Availability Zones (sites) are located. A region can have two or more AZs. These can include regions like US-East-1 or US-West-1.
- Availability Zone (AZ)
- An AZ consists of one or more discrete datacenters inter-connected by low latency links. Each site has it’s own redundant power, cooling, network, etc. Comparing these to a traditional colo or datacenter, these would be considered more resilient as a AZ can consist of multiple independent datacenters. These can include sites like US-East-1a or US-West-1a.
- VPC
- A logically isolated segment of the AWS cloud for tenants. Provides a mechanism to to secure and isolate environment from others. Can be exposed to the internet or other private network segments (other VPCs, or VPNs).
- S3
- Amazon’s object service which provides persistent object storage accessed via the S3 API. This is used for archival / restore.
- EBS
- Amazon’s volume / block service which provides persistent volumes that can be attached to AMIs.
- Cloud Formation Template (CFT)
- A Cloud Formation Template simplifies provisioning, but allowing you to define a “stack” of resources and dependencies. This stack can then be provisioned as a whole instead of each individual resource.
Cluster Architecture
From a high-level the Nutanix Clusters Portal is the main interface for provisioning Nutanix Clusters on AWS and interacting with AWS.
The provisioning process can be summarized with the following high-level steps:
- Create cluster in NC2 Portal
- Deployment specific inputs (e.g. Region, AZ, Instance type, VPC/Subnets, etc.)
- The NC2 Portal creates associated resources
- Host agent in Nutanix AMI checks-in with Nutanix Clusters on AWS
- Once all hosts as up, cluster is created
The following shows a high-level overview of the NC2A interaction:
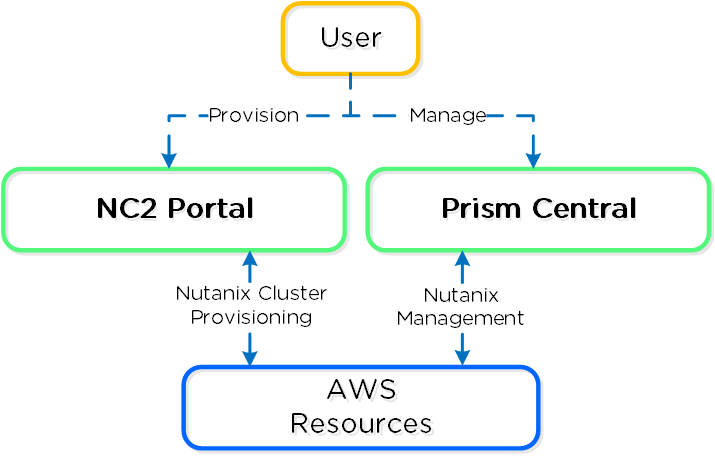 NC2A - Overview
NC2A - Overview
The following shows a high-level overview of a the inputs taken by the NC2 Portal and some created resources:
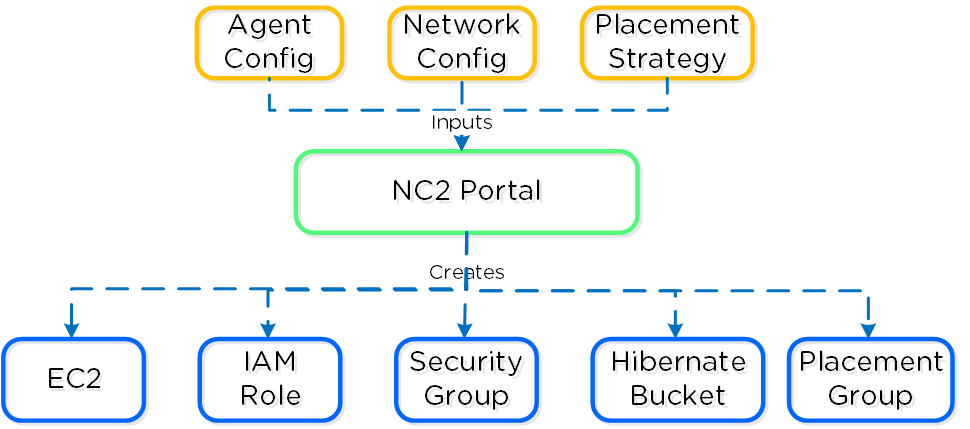 Nutanix Clusters on AWS - Cluster Orchestrator Inputs
Nutanix Clusters on AWS - Cluster Orchestrator Inputs
The following shows a high-level overview of a node in AWS:
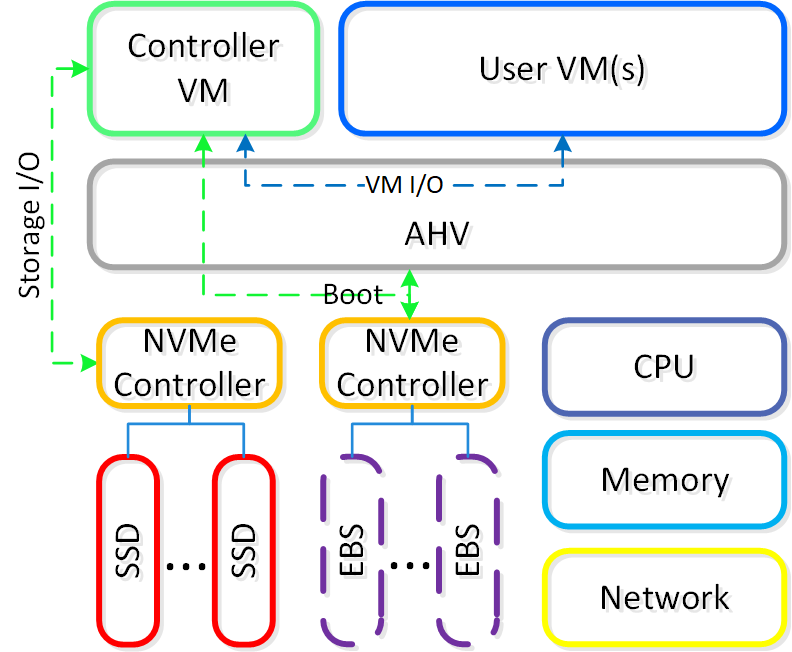 NC2A - Node Architecture
NC2A - Node Architecture
Given the hosts are bare metal, we have full control over storage and network resources similar to a typical on-premises deployment. For the CVM and AHV host boot, EBS volumes are used. NOTE: certain resources like EBS interaction run through the AWS Nitro card which appears as a NVMe controller in the AHV host.
Placement policy
Nutanix uses a partition placement strategy when deploying nodes inside an AWS Availability Zone. One Nutanix cluster can’t span different Availability Zones in the same Region, but you can have multiple Nutanix clusters replicating between each other in different zones or Regions. Using up to seven partitions, Nutanix places the AWS bare-metal nodes in different AWS racks and stripes new hosts across the partitions.
NC2 on AWS supports combining heterogenous node types in a cluster. You can deploy a cluster of one node type and then expand that cluster’s capacity by adding heterogenous nodes to it. This feature protects your cluster if its original node type runs out in the Region and provides flexibility when expanding your cluster on demand. If you’re looking to right-size your storage solution, support for heterogenous nodes can give you more instance options to choose from.
When combining instance types in a cluster, you must always maintain at least three nodes of the original type you deployed the base cluster with. You can expand or shrink the base cluster with any number of heterogenous nodes if at least three nodes of the original type remain and the cluster size stays within the limit of 28 nodes.
The following table and figure both refer to the cluster’s original instance type as Type A and its compatible heterogenous type as Type B.
Table: Supported Instance Type Combinations
| Type A | Type B |
|---|---|
| i3.metal | i3en.metal |
| i3en.metal | i3.metal |
| z1d.metal | m5d.metal |
| m5d.metal | z1d.metal |
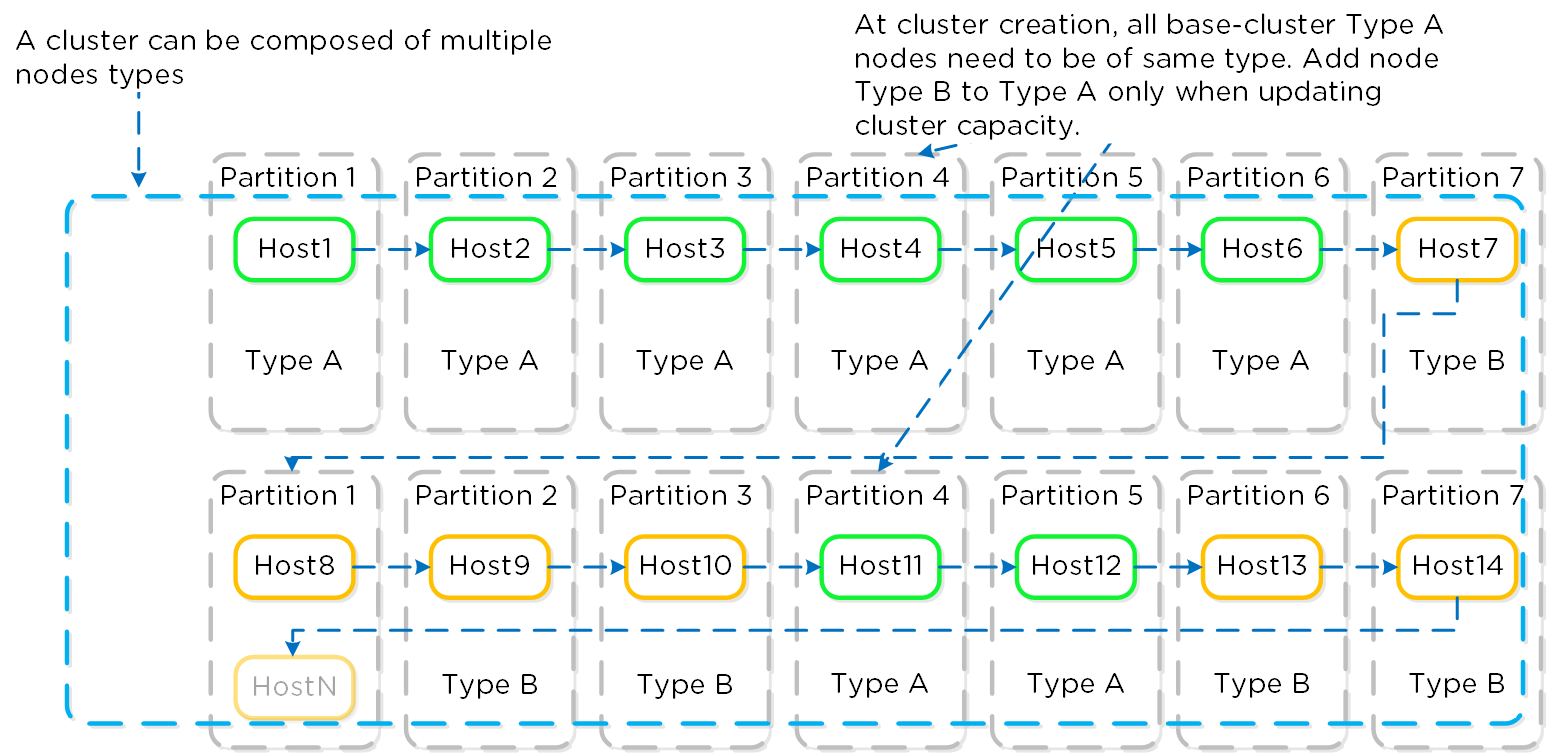 NC2A - Partition Placement
NC2A - Partition Placement
When you’ve formed the Nutanix cluster, the partition groups map to the Nutanix rack-awareness feature. AOS Storage writes data replicas to other racks in the cluster to ensure that the data remains available for both replication factor 2 and replication factor 3 scenarios in the case of a rack failure or planned downtime.
Storage
Storage for Nutanix Cloud Clusters on AWS can be broken down into two core areas:
- Core / Active
- Hibernation
Core storage is the exact same as you’d expect on any Nutanix cluster, passing the “local” storage devices to the CVM to be leveraged by Stargate.
Note
Instance Storage
Given that the "local" storage is backed by the AWS instance store, which isn't fully resilient in the event of a power outage / node failure additional considerations must be handled.
For example, in a local Nutanix cluster in the event of a power outage or node failure, the storage is persisted on the local devices and will come back when the node / power comes back online. In the case of the AWS instance store, this is not the case.
In most cases it is highly unlikely that a full AZ will lose power / go down, however for sensitive workloads it is recommended to:
- Leverage a backup solution to persist to S3 or any durable storage
- Replicate data to another Nutanix cluster in a different AZ/Region/Cloud (on-prem or remote)
One unique ability with NC2A is the ability to “hibernate” a cluster allowing you to persist the data while spinning down the EC2 compute instances. This could be useful for cases where you don’t need the compute resources and don’t want to continue paying for them, but want to persist the data and have the ability to restore at a later point.
When a cluster is hibernated, the data will be backed up from the cluster to S3. Once the data is backed up the EC2 instances will be terminated. Upon a resume / restore, new EC2 instances will be provisioned and data will be loaded into the cluster from S3.
Networking
Networking can be broken down into a few core areas:
- Host / Cluster Networking
- Guest / UVM Networking
- WAN / L3 Networking
Note
Native vs. Overlay
Instead of running our own overlay network, we decided to run natively on AWS subnets, this allows VMs running on the platform to natively communicate with AWS services with zero performance degradation.
NC2A are provisioned into an AWS VPC, the following shows a high-level overview of an AWS VPC:
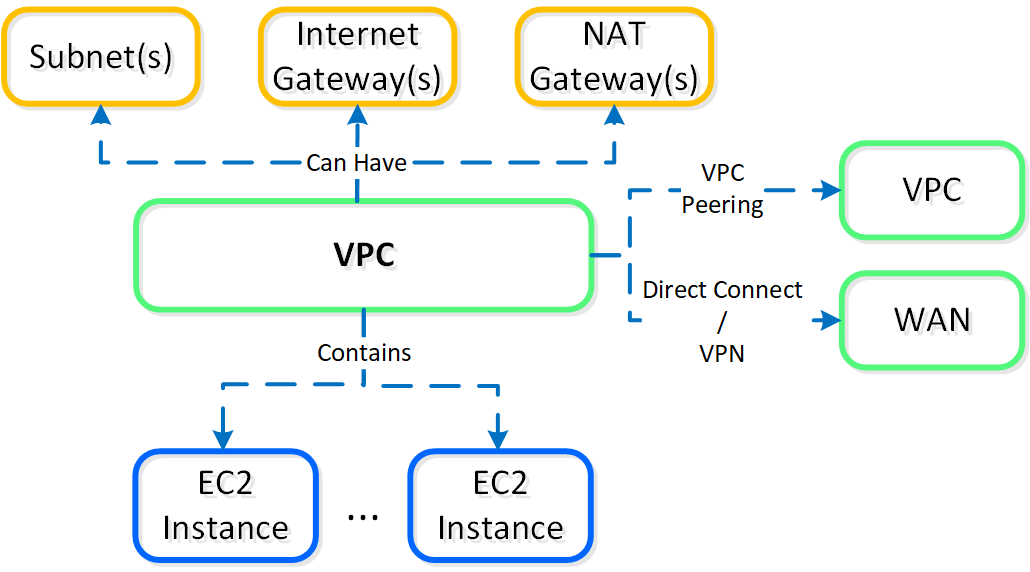 NC2A - AWS VPC
NC2A - AWS VPC
Note
New vs. Default VPC
AWS will create a default VPC/Subnet/Etc. with a 172.31.0.0/16 ip scheme for each region.
It is recommended to create a new VPC with associated subnets, NAT/Internet Gateways, etc. that fits into your corporate IP scheme. This is important if you ever plan to extend networks between VPCs (VPC peering), or to your existing WAN. This should be treated as you would treat any site on the WAN.
Host Networking
The hosts running on baremetal in AWS are traditional AHV hosts, and thus leverage the same OVS based network stack.
The following shows a high-level overview of a AWS AHV host’s OVS stack:
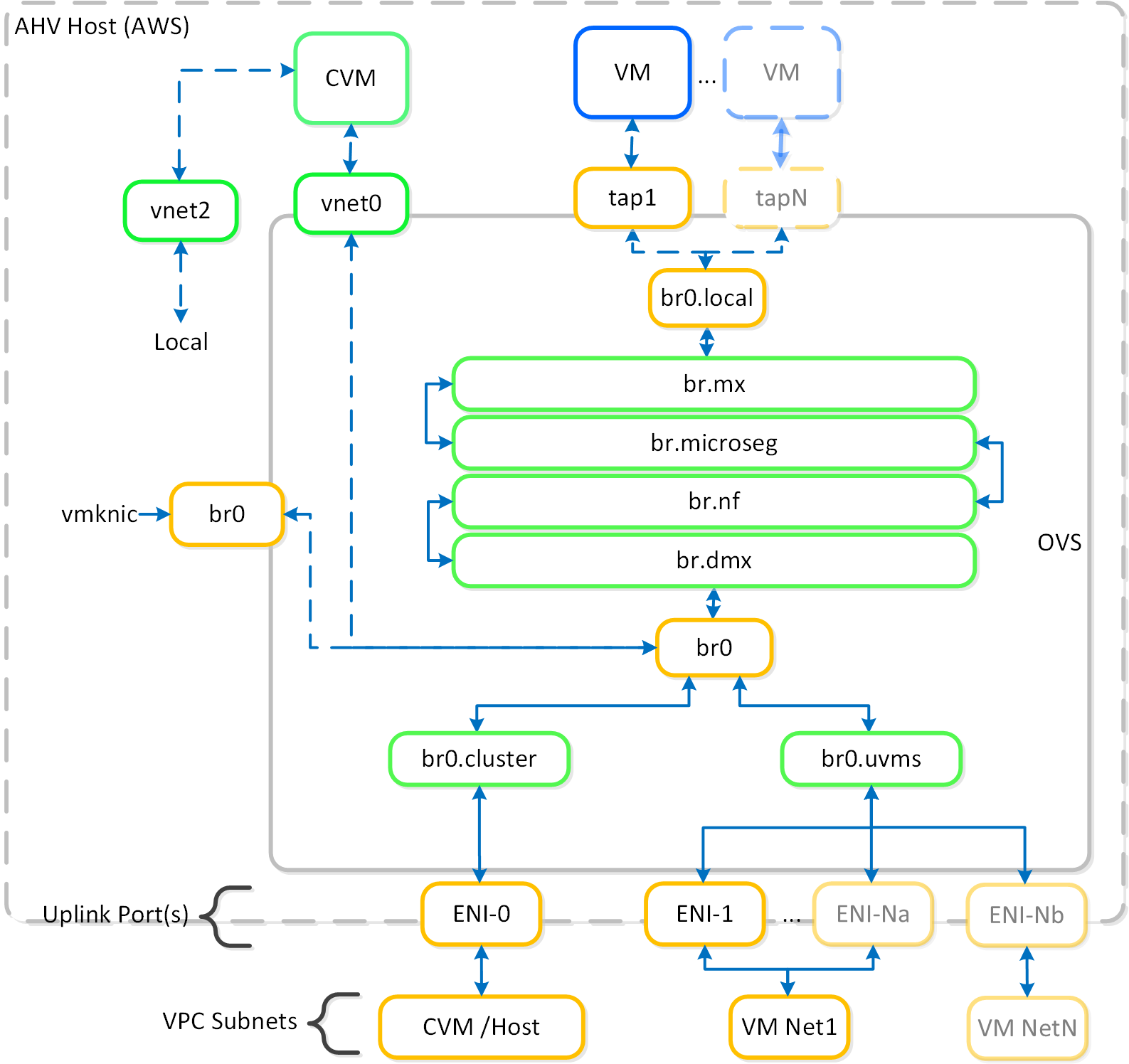 NC2A - OVS Architecture
NC2A - OVS Architecture
The OVS stack is relatively the same as any AHV host except for the addition of the L3 uplink bridge.
For UVM (Guest VM) networking, VPC subnets are used. A UVM network can be created during the cluster creation process or via the following steps:
From the AWS VPC dashboard, click on ‘subnets’ then click on ‘Create Subnet’ and input the network details:
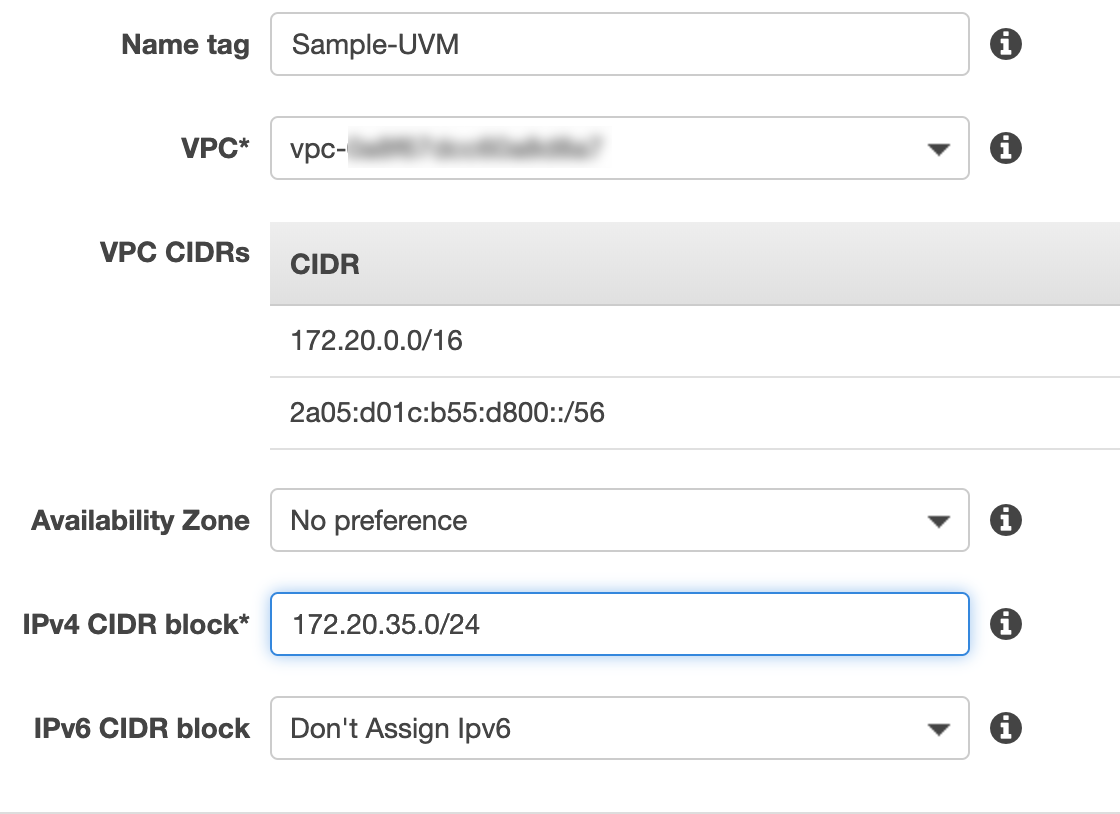 NC2A - OVS Architecture
NC2A - OVS Architecture
NOTE: the CIDR block should be a subset of the VPC CIDR range.
The subnet will inherit the route table from the VPC:
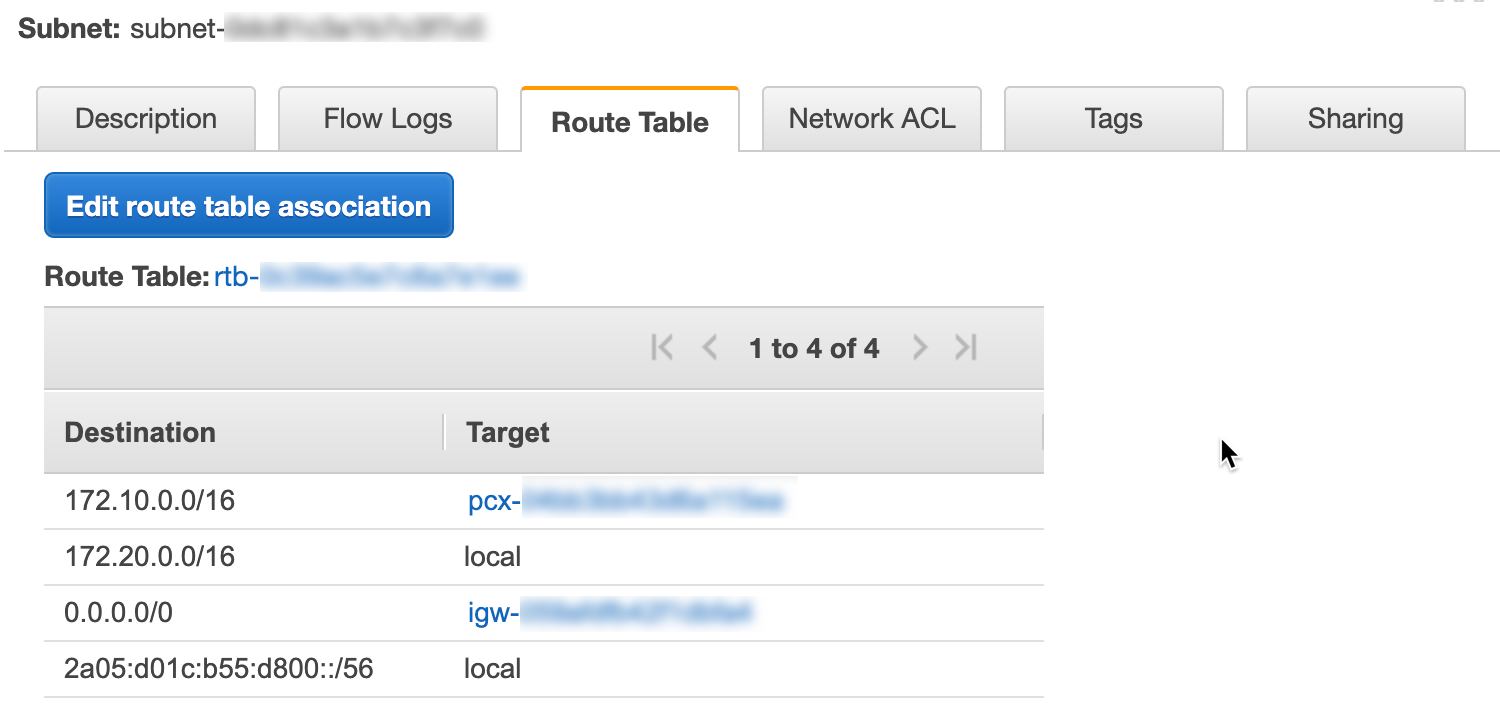 NC2A - Route Table
NC2A - Route Table
In this case you can see any traffic in the peered VPC will go over the VPC peering link and any external traffic will go over the internet gateway.
Once complete, you will see the network is available in Prism.
WAN / L3 Networking
In most cases deployments will not be just in AWS and will need to communicate with the external world (Other VPCs, Internet or WAN).
For connecting VPCs (in the same or different regions), you can use VPC peering which allows you to tunnel between VPCs. NOTE: you will need to ensure you follow WAN IP scheme best practices and there are no CIDR range overlaps between VPCs / subnets.
The following shows a VPC peering connection between a VPC in the eu-west-1 and eu-west-2 regions:
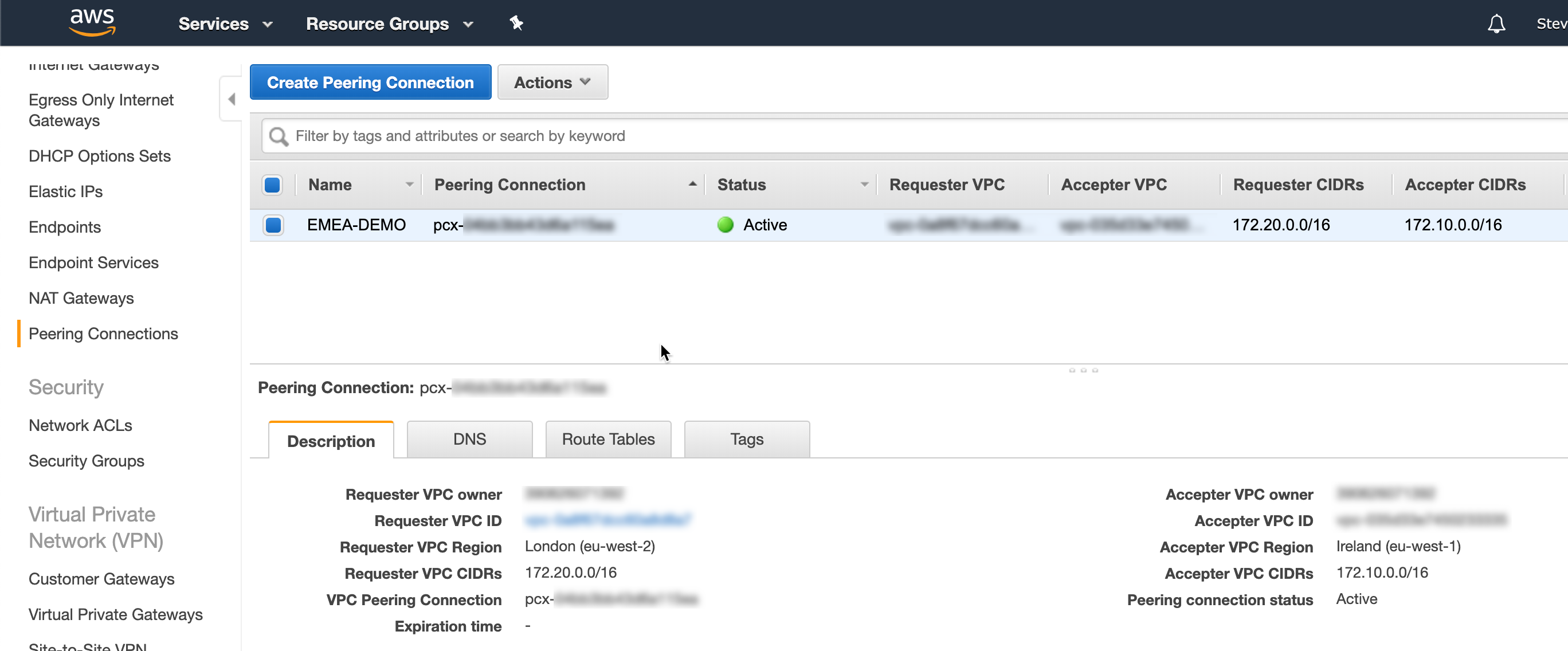 NC2A - VPC Peering
NC2A - VPC Peering
The route table for each VPC will then route traffic going to the other VPC over the peering connection (this will need to exist on both sides if communication needs to be bi-directional):
NC2A - Route Table
For network expansion to on-premises / WAN, either a VPN gateway (tunnel) or AWS Direct Connect can be leveraged.
Security
Given these resources are running in a cloud outside our full control security, data encryption and compliance is a very critical consideration.
The recommendations can be characterized with the following:
- Enable data encryption
- Only use private subnets (no public IP assignment)
- Lock down security groups and allowed ports / IP CIDR blocks
- For more granular security, leverage Flow
AWS Security Groups
With AWS security groups, you can limit access to the AWS CVMs, AHV host, and UVMs only from your on-premises management network and CVMs. You can control replication from on-premises to AWS down to the port level, and you can easily migrate workloads because replication software is embedded in the CVMs on both ends.
NC2 can help you save on the cost of additional compute that overlay networks require. You can also avoid the costs for management gateways, network controllers, edge devices, and storage incurred from adding appliances. A simpler system offers significant operational savings on maintenance and troubleshooting.
AOS 6.7 adds support for custom AWS Security Groups. Prior to this update, two main security groups provided native protection. The new enhancement provides additional flexibility so AWS security groups can apply to the Virtual Private Cloud (VPC) domain and at the cluster and subnet levels.
Custom AWS Security Groups are applied when the ENI is attached to the bare-metal host. You can use and re-use pre-created Security Groups across different clusters without additional scripting to maintain and support the prior custom Security Groups.
You can use the tags in the following list with any AWS Security Group, including custom Security Groups. The Cloud Network Service (CNS) uses these tags to evaluate which Security Groups to attach to the network interfaces. The CNS is a distributed service that runs in the CVM and provides cloud-specific back-end support for subnet management, IP address event handling, and security group management. The following list is arranged in dependency order.
- Scope: VPC
- Key: tag:nutanix:clusters:external
- Value: <none> (leave this tag blank)
You can use this tag to protect multiple clusters in the same VPC.
- Scope: VPC or cluster
- Key: tag:nutanix:clusters:external:cluster-uuid
- Value: <cluster-uuid>
This tag protects all the UVMs and interfaces that the CVM and AHV use.
- Scope: VPC, cluster, network, or subnet
- Key: tag:nutanix:clusters:external:networks
- Value: <cidr1, cidr2, cidr3>
This tag only protects the subnets you provide.
If you want to apply a tag based on the subnet or CIDR, you need to set both external and cluster-uuid for the network or subnet tag to be applied. The following subsections provide configuration examples.
Default Security Groups
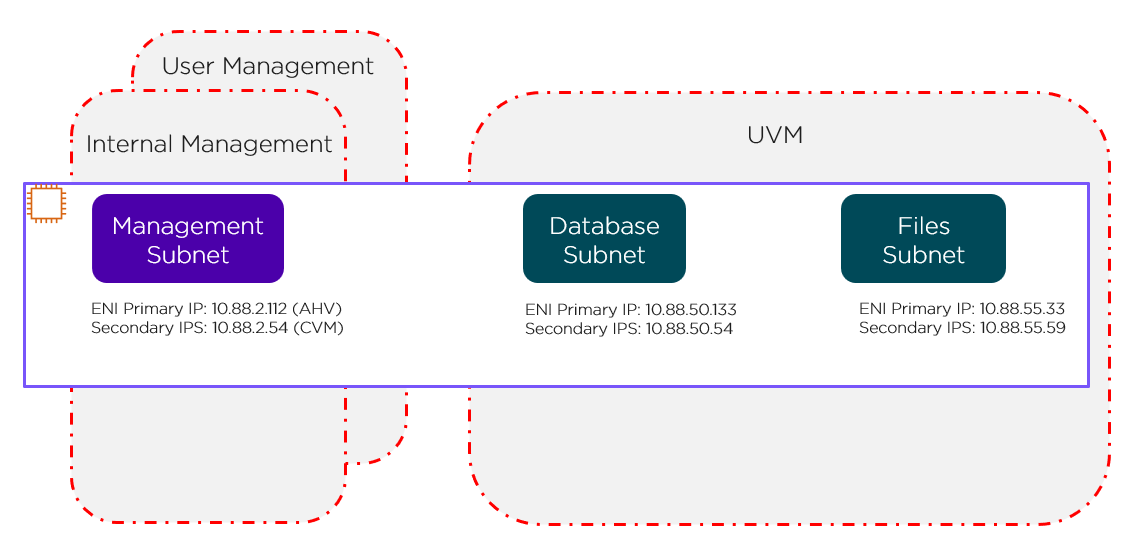
The red lines in the preceding figure represent the standard AWS Security Groups that deploy with the cluster.
- Internal management Security Group: Allows all internal traffic between all CVMs and AHV hosts (EC2 bare-metal hosts). Don’t edit this group without approval from Nutanix Support.
- User management Security Group: Allows users to access Prism Element and other services running on the CVM.
- UVM Security Group: Allows UVMs to talk to each other. By default, all UVMs on all subnets can talk to each other. This Security Group doesn’t offer subnet granularity.
VPC Level
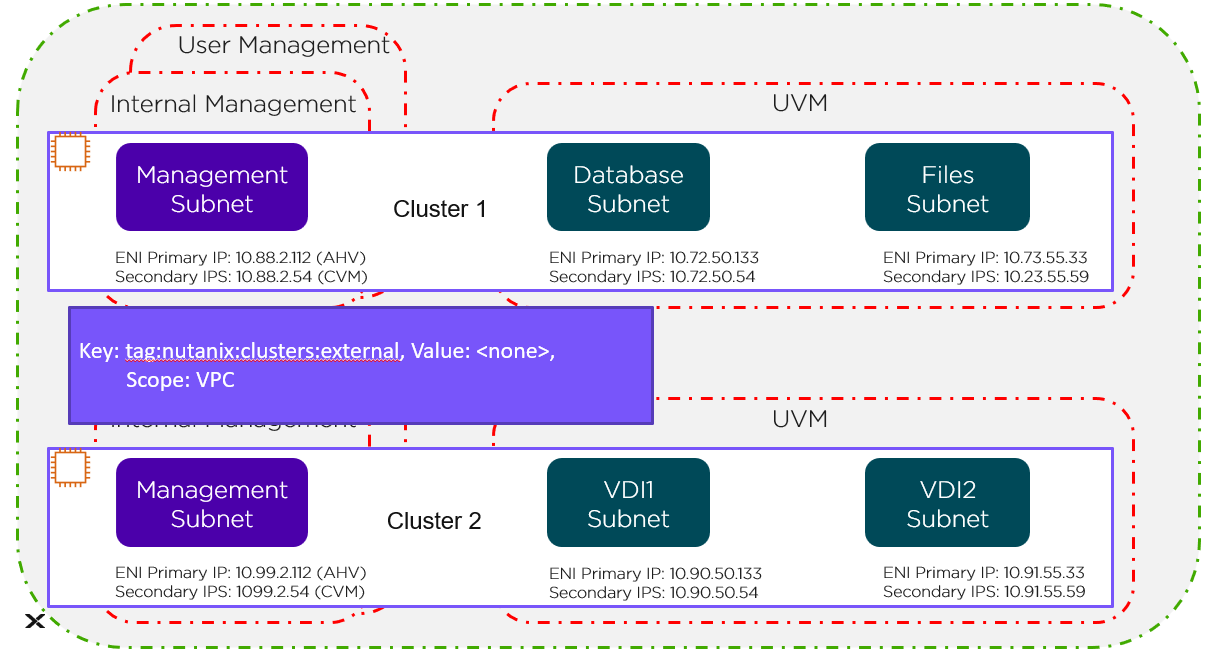
The green line in the preceding figure represents the VPC-level tag protecting Cluster 1 and Cluster 2.
Cluster Level
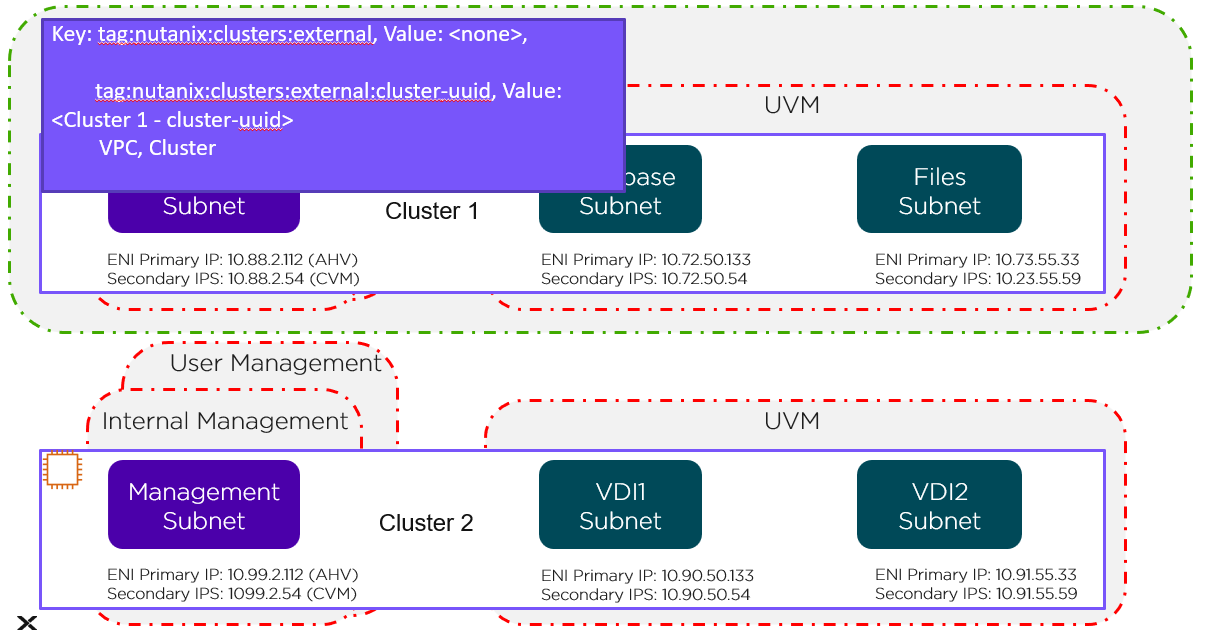
The green line in the preceding figure represents the cluster-level tag. Changes to these Security Groups affect the management subnet and all the UVMs running in Cluster 1.
Network Level
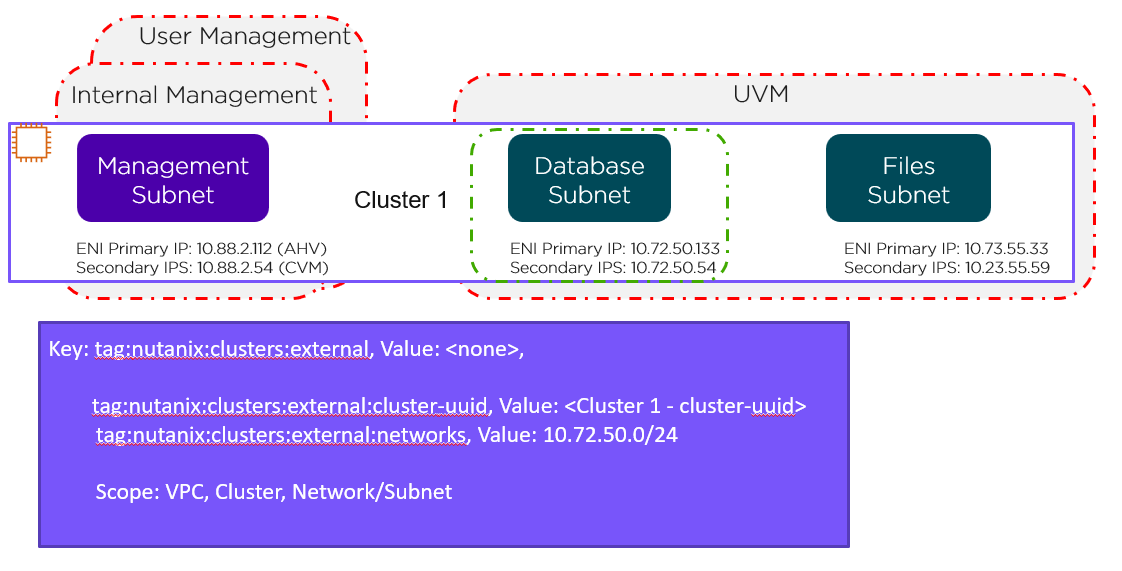
This network-level custom Security Group covers just the database subnet, as shown by the green line in the preceding figure. To cover the Files subnet with this Security Group, simply change the tag as follows:
- tag:nutanix:clusters:external:networks, Value: 10.72.50.0/24, 10.73.55.0/24
Usage and Configuration
The following sections cover how to configure and leverage NC2A.
The high-level process can be characterized into the following high-level steps:
- Create AWS Account(s)
- Configure AWS network resources (if necessary)
- Provision cluster(s) via Nutanix Clusters Portal
- Leverage cluster resources once provisioning is complete
- Protect your cluster
Native Backup with Nutanix Cluster Protection
Even when you migrate your application to the cloud, you still must provide all of the same day-two operations as you would if the application was on-premises. Nutanix Cluster Protection provides a native option for backing up Nutanix Cloud Clusters (NC2) running on AWS to S3 buckets, including user data and Prism Central with its configuration data. Cluster Protection backs up all user-created VMs and volume groups on the cluster.
As you migrate from on-premises to the cloud, you can be sure that there is another copy of your applications and data in the event of an AWS Availability Zone (AZ) failure. Nutanix already provides native protection for localized failures at the node and rack level, and Cluster Protection extends that protection to the cluster’s AZ. Because this service is integrated, high-performance applications are minimally affected as the backup process uses native AOS snapshots to send the backup directly to S3.
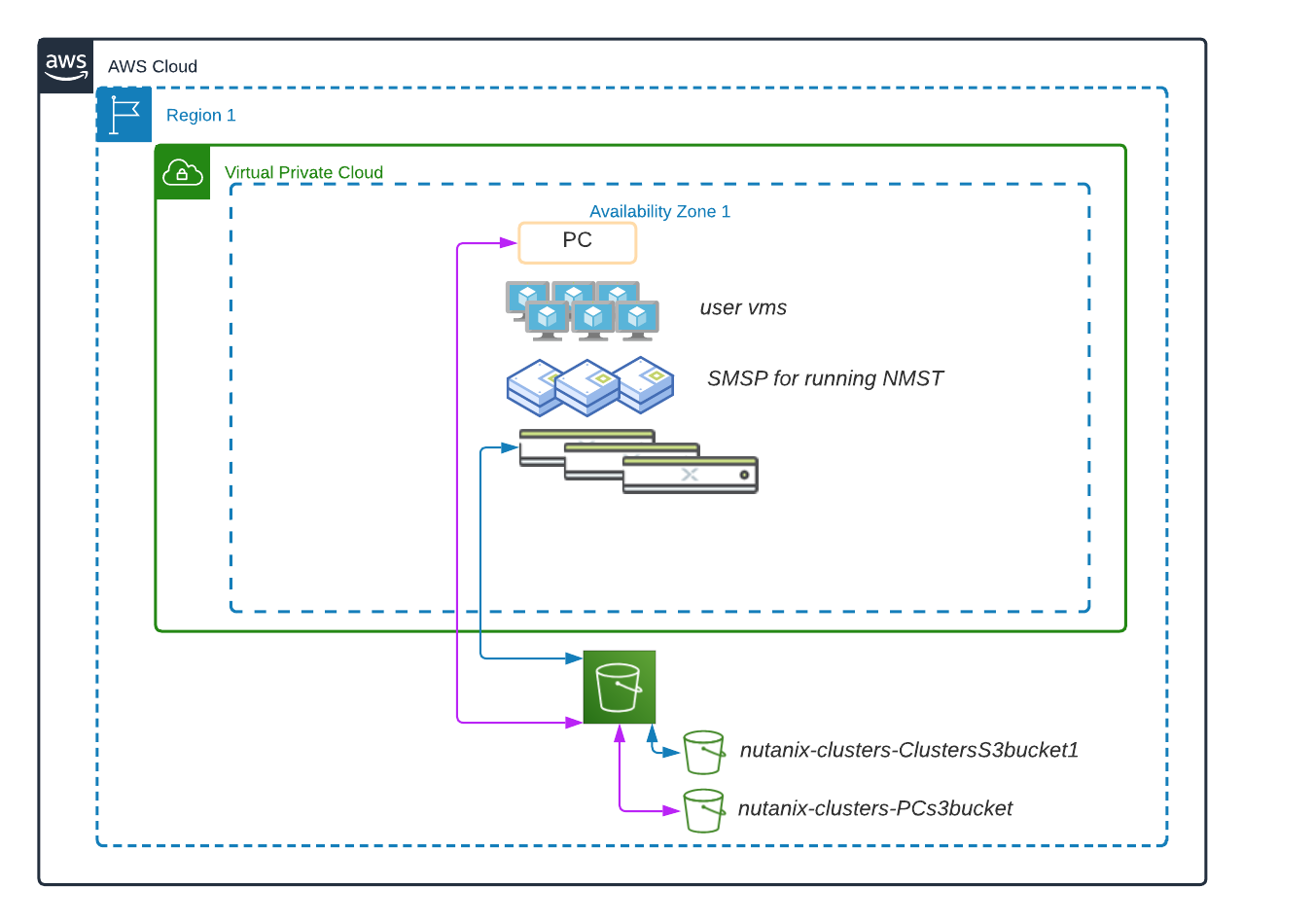
Two Nutanix services help deliver Cluster Protection:
- Prism Central Disaster Recovery is responsible for backing up the Prism Central data. Instead of backing up to an AOS storage container, you can now supply a new S3 bucket to point the backup to.
- Nutanix Multicloud Snapshot Technology (NMST) replicates native Nutanix AOS snapshots to object storage. In the Cluster Protection design, the you supply a second new S3 bucket in AWS to send all the protected clusters’ snapshots to the same S3 bucket. The Cloud Snapshot Engine runs on the Prism Central instance in AWS.
The following high-level process describes how to protect your clusters and Prism Central in AWS.
- Deploy a one- or three-node Prism Central instance in AWS.
- Create two S3 Buckets: one for Prism Central and one for your cloud clusters.
- Enable Prism Central protection.
- Deploy NMST.
- Protect your AWS cloud clusters.
The system takes both the Prism Central and AOS snapshots every hour and retains up to two snapshots in S3. A Nutanix Disaster Recovery category protects all of the user-created VMs and volume groups on the clusters. A service watches for create or delete events and assigns them a Cluster Protection category.
The following high-level process describes how to recover your Prism Central instances and clusters on AWS.
- The NC2 console automatically deploys a new NC2 cluster during the recovery process.
- Add your Prism Central subnet and any user VM networks to your recreated cloud cluster.
- Recover your Prism Central configuration from the S3 bucket.
- Register your Prism Central instance with the recovered cluster.
- Recover NMST.
- Create a recovery plan.
- Run the recovery plan from Prism Central.
Once the NMST is recovered, you can restore using the recovery plan in Prism Central. The recovery plan has all the VMs you need to restore. By using Nutanix Disaster Recovery with this new service, administrators can easily recover when disaster strikes.